在构建人工智能应用时,工程团队使用向量数据库,常面临管理多个数据库和复杂同步逻辑的情况。
而 Timescale 提出了一种新的方法——“向量化器(Vectorizer)”,它可以自动化创建嵌入向量、生成嵌入表、同步嵌入数据等,使构建 RAG(检索增强生成)、搜索和 AI 代理等系统更加简便。
Vectorizer 基于 PostgreSQL 实现,通过自动同步嵌入向量,解决了向量数据库存在的两大核心问题:
-
嵌入与源数据分离:向量数据库(如 Pinecone)将嵌入向量视为独立的数据,与源数据(如文本、图像)脱节,迫使开发团队同时管理多个系统(如 DynamoDB、OpenSearch),来处理不同类型的数据和搜索功能。
-
复杂的同步操作:每次数据更新、删除时,需要在多个数据库中执行同步操作,增加了系统复杂性和出错的可能性,带来了维护成本的增加。
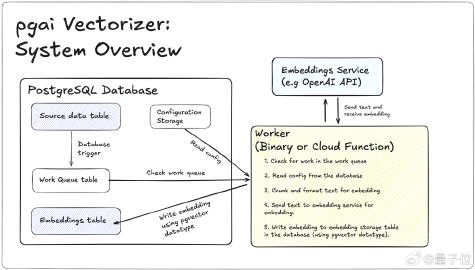
如【图】所示,Vectorizer 的工作原理如下:
• 检查工作队列表:当源数据表(Source data table)中的数据发生变化时,数据库触发器(Database trigger)自动触发,将相关的任务添加到工作队列表(Work Queue table)。
• 检查工作队列:工人(Worker)周期性检查队列中是否有待处理的任务。
• 读取配置:从配置存储(Configuration Storage)中读取如何处理数据的具体设置,如分块大小、格式化模板等。
• 数据处理:按照读取的配置对数据进行必要的分块和格式化处理,以便嵌入服务能有效地处理文本。
• 发送文本并接收嵌入向量:处理后的文本被发送到外部嵌入服务(如 OpenAI API),该服务返回相应的嵌入向量。
• 将嵌入写回数据库:接收到的嵌入向量使用 pgvector 数据类型存入数据库的嵌入表(Embeddings table),以便后续使用或查询。
通过这一流程,Vectorizer 就能自动同步嵌入向量与基础数据的变化(添加、删除、更新),以确保嵌入与源数据同步,简化数据管理。
感兴趣的小伙伴可以点击  网页链接
网页链接