kokoro-tts Public
A CLI text-to-speech tool using the Kokoro model, supporting multiple languages, voices (with blending), and various input formats including EPUB books and PDF documents.
huggingface.co/hexgrad/Kokoro-82M
Open in github.dev Open in a new github.dev tab Open in codespace
| Name | Name |
Last commit message |
Last commit date |
|
|---|---|---|---|---|
|
chore(config): update dependency versions and project version a48f502 · |
||||
|
chore(config): update dependency versions and project version |
||||
A CLI text-to-speech tool using the Kokoro model, supporting multiple languages, voices (with blending), and various input formats including EPUB books and PDF documents.
使用 Kokoro 模型的 CLI 文本转语音工具,支持多种语言、语音(带混合)和各种输入格式,包括 EPUB 书籍和 PDF 文档。
Features 特征
- Multiple language and voice support
多语言和语音支持 - Voice blending with customizable weights
具有可自定义权重的语音混合 - EPUB, PDF and TXT file input support
支持 EPUB、PDF 和 TXT 文件输入 - Standard input (stdin) and
|piping from other programs
来自其他程序的标准输入 (stdin) 和|管道 - Streaming audio playback
流式音频播放 - Split output into chapters
将输出拆分为多个章节 - Adjustable speech speed 可调节的语速
- WAV and MP3 output formats
WAV 和 MP3 输出格式 - Chapter merging capability
章节合并功能 - Detailed debug output option
详细的调试输出选项 - GPU Support GPU 支持
Demo 演示
Kokoro TTS is an open-source CLI tool that delivers high-quality text-to-speech right from your terminal. Think of it as your personal voice studio, capable of transforming any text into natural-sounding speech with minimal effort.
Kokoro TTS 是一种开源 CLI 工具,可直接从您的终端提供高质量的文本转语音。将其视为您的个人语音工作室,能够以最小的努力将任何文本转换为听起来自然的语音。
demo.mp4
Demo Audio (MP3) | Demo Audio (WAV)
演示音频 (MP3) | 演示音频 (WAV)
TODO 都
- Add GPU support
添加 GPU 支持 - Add PDF support
添加 PDF 支持 - Add GUI 添加 GUI
Prerequisites 先决条件
- Python 3.12 Python 3.12 版
Installation 安装
- Clone the repository:克隆存储库:
git clone https://github.com/nazdridoy/kokoro-tts.git
cd kokoro-tts
- Install required packages:
安装所需的软件包:
pip install -r requirements.txt
or 或
uv sync
Note: You can also use uv as a faster alternative to pip for package installation. (This is a uv project) Note: Python>=3.13 is not currently supported.
注意:您还可以使用 uv 作为 pip 的更快替代方案来安装软件包。(这是一个 uv 项目)注意:当前不支持 Python>=3.13。
- Download the required model files:
下载所需的模型文件:
# Download either voices.json or voices.bin (bin is preferred)
wget https://github.com/nazdridoy/kokoro-tts/releases/download/v1.0.0/voices-v1.0.bin
# Download the model
wget https://github.com/nazdridoy/kokoro-tts/releases/download/v1.0.0/kokoro-v1.0.onnx
Note: The script will automatically use voices.bin if present, falling back to voices.json if bin is not available.
注意:如果存在,脚本将自动使用 voices.bin,如果 bin 不可用,则回退到 voices.json。
| Category 类别 | Voices 声音 | Language Code 语言代码 |
|---|---|---|
| 🇺🇸 👩 | af_alloy, af_aoede, af_bella, af_heart, af_jessica, af_kore, af_nicole, af_nova, af_river, af_sarah, af_sky af_alloy、af_aoede、af_bella、af_heart、af_jessica、af_kore、af_nicole、af_nova、af_river、af_sarah af_sky | en-us |
| 🇺🇸 👨 | am_adam, am_echo, am_eric, am_fenrir, am_liam, am_michael, am_onyx, am_puck | en-us |
| 🇬🇧 | bf_alice, bf_emma, bf_isabella, bf_lily, bm_daniel, bm_fable, bm_george, bm_lewis | en-gb |
| 🇫🇷 | ff_siwis | fr-fr |
| 🇮🇹 | if_sara, im_nicola | it |
| 🇯🇵 | jf_alpha, jf_gongitsune, jf_nezumi, jf_tebukuro, jm_kumo | ja |
| 🇨🇳 | zf_xiaobei, zf_xiaoni, zf_xiaoxiao, zf_xiaoyi, zm_yunjian, zm_yunxi, zm_yunxia, zm_yunyang | cmn |
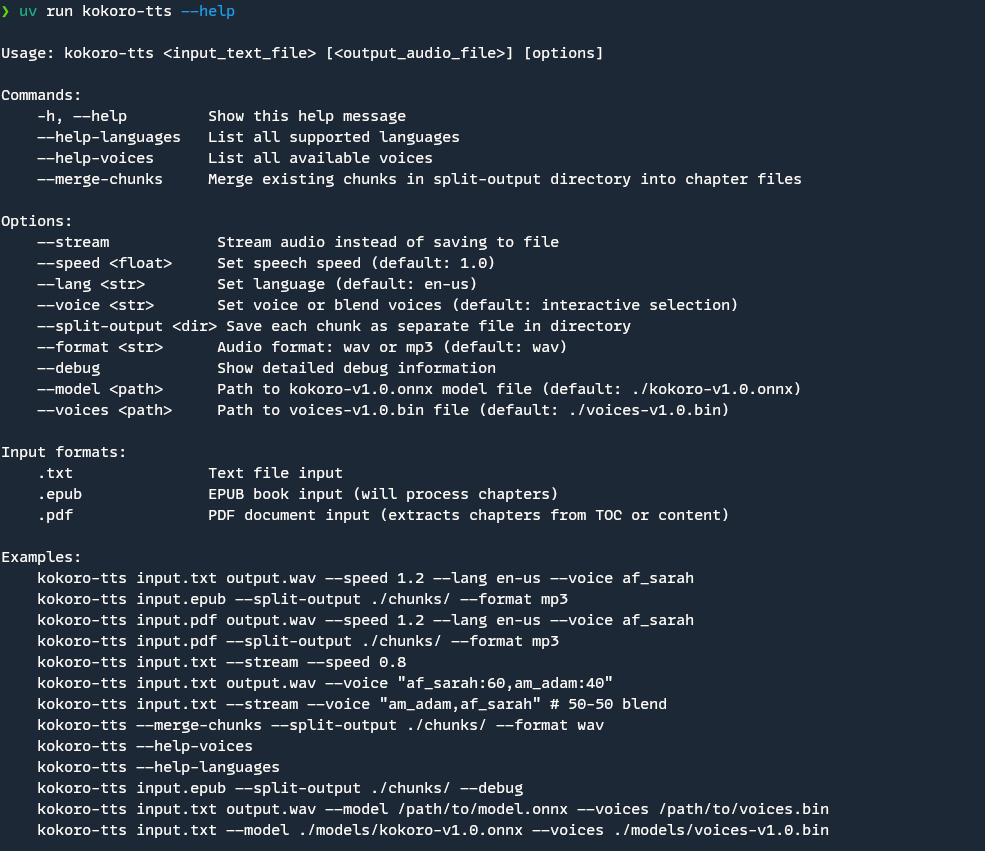
Usage
Basic usage:
./kokoro-tts <input_text_file> [<output_audio_file>] [options]
Commands
-h, --help: Show help message--help-languages: List supported languages--help-voices: List available voices--merge-chunks: Merge existing chunks into chapter files
Options
--stream: Stream audio instead of saving to file--speed <float>: Set speech speed (default: 1.0)--lang <str>: Set language (default: en-us)--voice <str>: Set voice or blend voices (default: interactive selection)- Single voice: Use voice name (e.g., "af_sarah")
- Blended voices: Use "voice1:weight,voice2:weight" format
--split-output <dir>: Save each chunk as separate file in directory--format <str>: Audio format: wav or mp3 (default: wav)--debug: Show detailed debug information during processing
Input Formats
.txt: Text file input.epub: EPUB book input (will process chapters).pdf: PDF document input (extracts chapters from TOC or content)
Examples
# Basic usage with output file
kokoro-tts input.txt output.wav --speed 1.2 --lang en-us --voice af_sarah
# Read from standard input (stdin)
echo "Hello World" | kokoro-tts /dev/stdin --stream
cat input.txt | kokoro-tts /dev/stdin output.wav
# Use voice blending (60-40 mix)
kokoro-tts input.txt output.wav --voice "af_sarah:60,am_adam:40"
# Use equal voice blend (50-50)
kokoro-tts input.txt --stream --voice "am_adam,af_sarah"
# Process EPUB and split into chunks
kokoro-tts input.epub --split-output ./chunks/ --format mp3
# Stream audio directly
kokoro-tts input.txt --stream --speed 0.8
# Merge existing chunks
kokoro-tts --merge-chunks --split-output ./chunks/ --format wav
# Process EPUB with detailed debug output
kokoro-tts input.epub --split-output ./chunks/ --debug
# Process PDF and split into chapters
kokoro-tts input.pdf --split-output ./chunks/ --format mp3
# List available voices
kokoro-tts --help-voices
# List supported languages
kokoro-tts --help-languages
EPUB Processing
- Automatically extracts chapters from EPUB files
- Preserves chapter titles and structure
- Creates organized output for each chapter
- Detailed debug output available for troubleshooting
Audio Processing
- Chunks long text into manageable segments
- Supports streaming for immediate playback
- Voice blending with customizable mix ratios
- Progress indicators for long processes
- Handles interruptions gracefully
Output Options
- Single file output
- Split output with chapter organization
- Chunk merging capability
- Multiple audio format support
Debug Mode
- Shows detailed information about file processing
- Displays NCX parsing details for EPUB files
- Lists all found chapters and their metadata
- Helps troubleshoot processing issues
Input Options
- Text file input (.txt)
- EPUB book input (.epub)
- Standard input (stdin)
- Supports piping from other programs
Contributing
This is a personal project. But if you want to contribute, please feel free to submit a Pull Request.
License
This project is licensed under the MIT License. See the LICENSE file for details.
Acknowledgments
Releases 5
Packages
No packages published