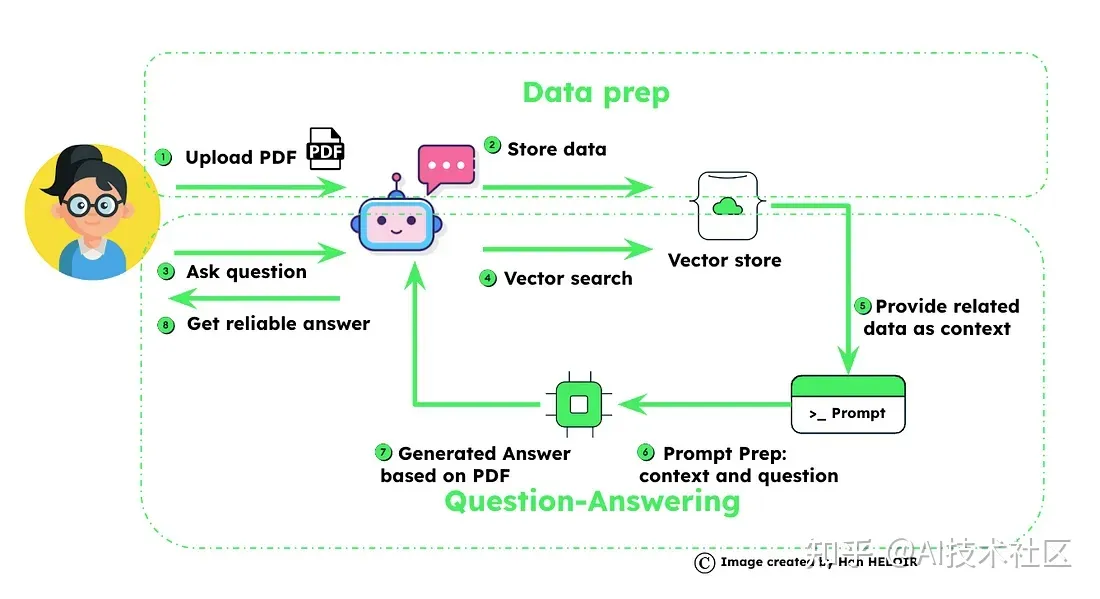
Langchain在构建智能聊天机器人中的角色
LangChain是一个用于语言模型驱动应用程序的强大框架,在构建智能聊天机器人方面具有颠覆性的作用。以下是LangChain脱颖而出的一些关键点:
上下文感知
LangChain使应用程序,特别是聊天机器人,能够根据来自各种来源的上下文信息,如提示说明和历史交互,进行理解和响应。
推理能力
该框架赋予应用程序有效推理的能力,使它们能够根据提供的上下文做出明智的决策。
主要组件:
LangChain库: 具有各种组件的Python和JavaScript库,具有接口和集成。 将组件组合成链和代理的基本运行时,其中包括聊天机器人等现成的实现。
LangChain是您可能采用的一个关键选择,用于开发具有上下文感知、推理能力和对信息的高效访问的智能聊天机器人。随着我们深入探讨LangChain的机制,展示其在构建尤其是与MongoDB一起在企业环境中打造尖端对话AI应用程序方面的娴熟技能,请继续关注。
逐步指南:实施您自己的聊天机器人
通过本指南,您将获得以下收益:
- 对RAG聊天机器人创建工作流程的清晰理解。
- 熟练运用LangChain的主要功能,并利用MongoDB的本机集成。
- 访问一个用户友好的UI,支持PDF上传,并通过Gradio轻松提问。
此外,您的应用程序界面将包含两个选项卡:一个用于上传PDF文件,另一个用于提问。
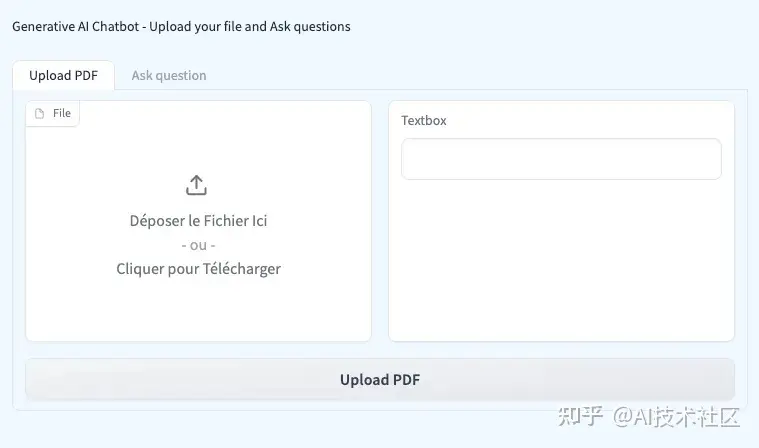
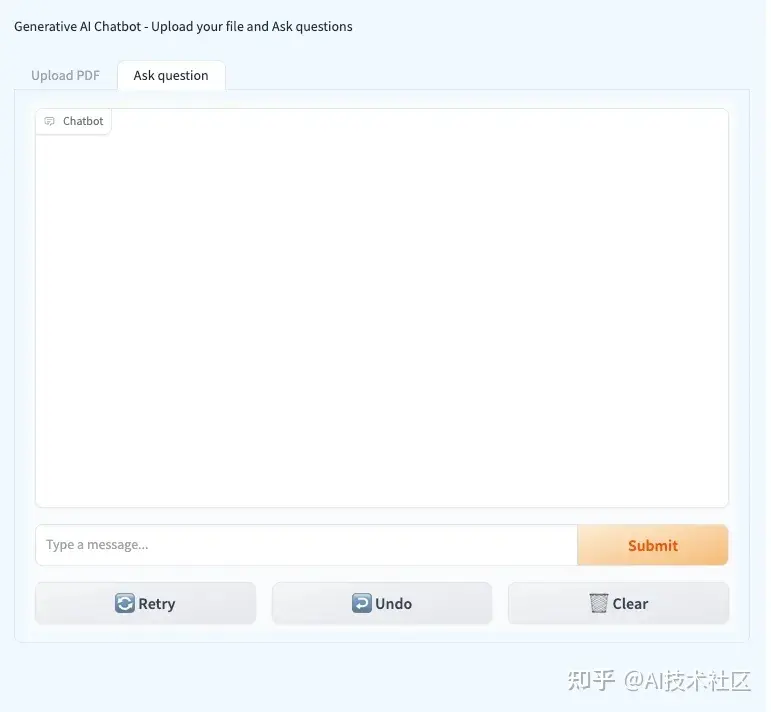
正如之前提到的,聊天机器人创建过程包含两个部分。初始步骤致力于建立知识库:
数据/PDF处理工作流程
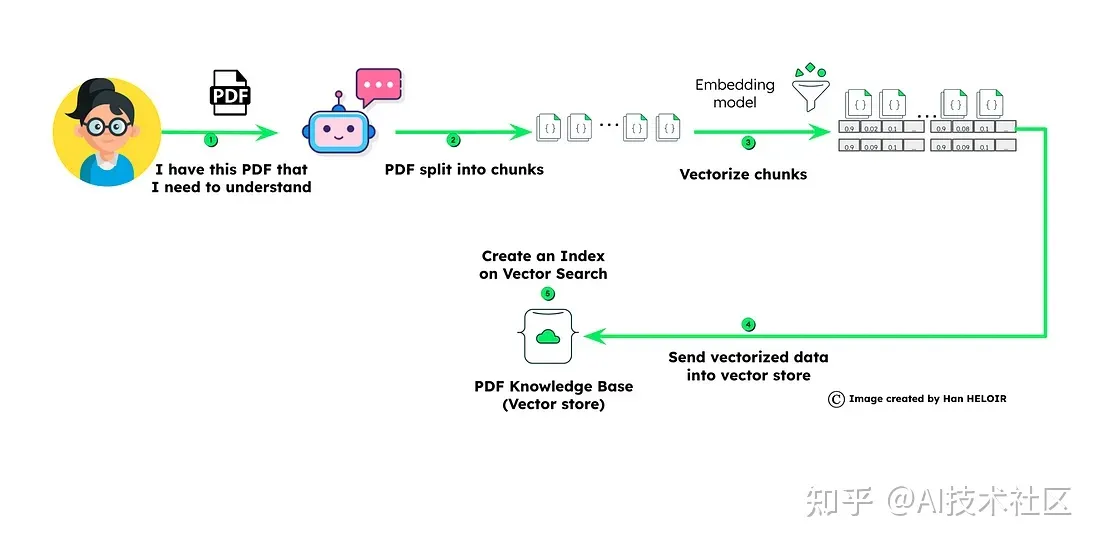
加载数据
初始步骤涉及获取用于问答的必要数据。这可以通过从网页或PDF文档中提取信息来实现。
数据块
一旦获取数据,它会被分割成易处理的块。这确保了信息的高效处理。
生成嵌入
每个分段块都经历嵌入过程。这种转换将文本转换为适合分析的数值表示。
MongoDB 矢量存储
生成的嵌入找到了它们在MongoDB中的家园,在那里它们被存储以便在问答阶段快速检索。
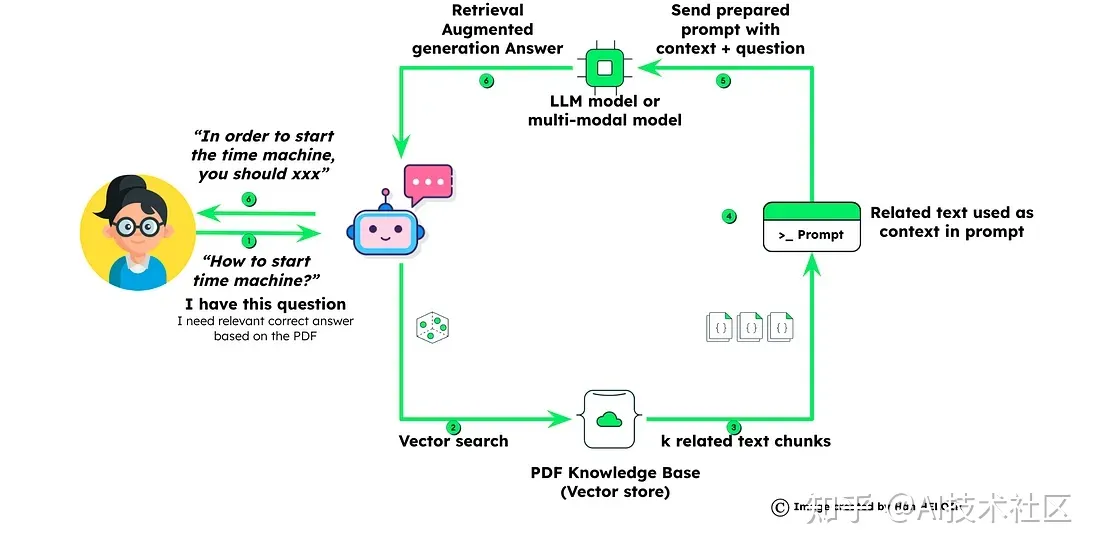
检索增强生成问答工作流程
问题嵌入: 当用户提出问题时,会生成该特定问题的嵌入。这一步为将问题与存储在MongoDB Atlas中的数据进行比较做准备。 检索相似块:
利用MongoDB的矢量搜索功能,系统检索与第一部分中准备的最符合提出问题的相关数据块。 通过上下文创建和问题准备提示:
检索到的数据块和用户的问题被合并,以创建全面的上下文。该上下文作为为大型语言模型(LLM)制定查询的基础。 通过RAG进行定制答案生成:
装备了提供的上下文的LLM模型生成定制的答案,该答案特定于用户的问题和数据集。这确保了个性化和准确的响应。
[[3ab195b99888acf0141374336ec8bf16_MD5.webp|Open: afd0edddf8c501fcb630f3472a6c4a45_MD5.webp]]
[[3ab195b99888acf0141374336ec8bf16_MD5.webp|Open: 3ab195b99888acf0141374336ec8bf16_MD5.webp]]
现在让我们详细讲解代码:
导入库并设置环境
import os
import re
from openai import OpenAI
import time
from dotenv import load_dotenv
from pymongo import MongoClient
from langchain.chat_models import ChatOpenAI
from langchain.schema import AIMessage, HumanMessage
from langchain.llms import OpenAI
from langchain.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import MongoDBAtlasVectorSearch
from langchain.chains import RetrievalQA
from langchain.schema.language_model import BaseLanguageModel
import gradio as gr
此部分包括导入必要的库和模块,用于各种功能,如与MongoDB交互,处理PDF,利用语言模型以及使用Gradio创建用户界面。
设置环境和MongoDB连接
# 从.env文件加载环境变量
load_dotenv(override=True)
# 设置MongoDB连接详细信息
OPENAI_API_KEY = os.environ["OPENAI_API_KEY"]
MONGO_URI = os.environ["MONGO_URI"]
DB_NAME = "pdfchatbot"
COLLECTION_NAME = "pdfText"
ATLAS_VECTOR_SEARCH_INDEX_NAME = "vector_index"
# 使用API密钥初始化OpenAIEmbeddings
embeddings = OpenAIEmbeddings(openai_api_key=OPENAI_API_KEY)
# 定义字段名称
EMBEDDING_FIELD_NAME = "embedding"
TEXT_FIELD_NAME = "text"
# 连接到MongoDB
client = MongoClient(MONGO_URI)
db = client[DB_NAME]
collection = db[COLLECTION_NAME]
在这里,加载环境变量,包括OpenAI和MongoDB连接详细信息的API密钥。代码使用API密钥初始化OpenAIEmbeddings并建立与MongoDB的连接。
PDF处理函数
def process_pdf(file,progress=gr.Progress()):
progress(0, desc="Starting")
time.sleep(1)
progress(0.05)
new_string = ""
for letter in progress.tqdm(file.name, desc="Uploading Your PDF into MongoDB Atlas"):
time.sleep(0.25)
loader = PyPDFLoader(file.name)
pages = loader.load_and_split()
# 打印加载的页面
print(pages)
# 将文本分割成文档
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
docs = text_splitter.split_documents(pages)
# 删除字母之间的单个空格并替换双空格
# docs_cleaned = [re.sub(r'\s+', ' ', doc.replace(' ', '')) for doc in docs]
# 将'Document'对象转换为字符串
docs_as_strings = [str(doc) for doc in docs]
# 使用嵌入设置MongoDBAtlasVectorSearch
vectorStore = MongoDBAtlasVectorSearch(
collection, embeddings, index_name=ATLAS_VECTOR_SEARCH_INDEX_NAME
)
# 将文档插入MongoDB Atlas Vector Search
docsearch = vectorStore.from_documents(
docs,
embeddings,
collection=collection,
index_name=ATLAS_VECTOR_SEARCH_INDEX_NAME,
)
return docsearch
定义一个名为process_pdf的函数,用于处理PDF文档,包括加载、分割和存储在MongoDB Atlas中。
查询和显示函数
定义一个名为query_and_display的函数,负责查询MongoDB Atlas Vector Search,检索相关文档,并在控制台中显示结果。
def query_and_display(query,history):
history_langchain_format = []
for human, ai in history:
history_langchain_format.append(HumanMessage(content=human))
history_langchain_format.append(AIMessage(content=ai))
history_langchain_format.append(HumanMessage(content=query))
# 使用嵌入设置MongoDBAtlasVectorSearch
vectorStore = MongoDBAtlasVectorSearch(
collection,
OpenAIEmbeddings(openai_api_key=OPENAI_API_KEY),
index_name=ATLAS_VECTOR_SEARCH_INDEX_NAME,
)
print(query)
# 查询MongoDB Atlas Vector Search
print("---------------")
docs = vectorStore.max_marginal_relevance_search(query, K=5)
llm = OpenAI(openai_api_key=OPENAI_API_KEY, temperature=0)
retriever = vectorStore.as_retriever(
search_type="similarity",
search_kwargs={"k": 5},
)
for document in retriever:
print(str(document) + "\n")
qa = RetrievalQA.from_chain_type(
llm, chain_type="stuff", retriever=retriever
)
retriever_output = qa.run(query)
print(retriever_output)
return retriever_output
Gradio用户界面
with gr.Blocks(css=".gradio-container {background-color: AliceBlue}") as demo:
gr.Markdown("Generative AI Chatbot - Upload your file and Ask questions")
with gr.Tab("Upload PDF"):
with gr.Row():
pdf_input = gr.File()
pdf_output = gr.Textbox()
pdf_button = gr.Button("Upload PDF")
with gr.Tab("Ask question"):
gr.ChatInterface(query_and_display)
pdf_button.click(process_pdf, inputs=pdf_input, outputs=pdf_output)
demo.launch()
设置Gradio用户界面,包括两个选项卡(“上传PDF”和“提问”),并配有相应的输入和输出组件。
结论
总之,我们从新手到由MongoDB和Langchain驱动的聊天机器人英雄的旅程简直是一场奇迹。
通过RAG,我们克服了与大型语言模型相关的挑战,确保了精确和具有上下文相关性的响应。MongoDB Atlas Vector Search是我们可靠的盟友,提供具备企业级准备性的解决方案,具有无缝集成和可扩展性。
这不仅是一个结论;这是一个开始。在您深入研究聊天机器人的过程中,愿您的旅程像那次非凡的时光机骑行一样充满魔力!