一. 意图识别
-
获取用户输入内容,进行必要的意图识别和关键词提取,比如用户输入的是“想去日本旅游,需要一个旅行计划”,拆解之后得到的关键词是: japan-trip,任务类型为:travel
-
如果用户输入的需求比较简单,不能识别用户的意图,此步骤可以引导用户继续对话,补充更多的信息,或者上传文档 / 图片等资料
二. 任务初始化
-
用识别出来的任务关键词创建任务文件夹,启动 docker 容器,为后续的任务执行做环境隔离
-
任务执行过程中的内容产物,写入到任务文件夹,任务结束之后清理 docker 容器
三. 步骤规划
-
使用意图识别的结果 + 补充背景信息,请求一个推理模型,对任务进行步骤拆分
-
将任务拆分的步骤信息,写入到任务文件夹的 http://todo.md四. 任务执行
-
遍历任务文件夹中的 http://todo.md,[ ] 表示待执行的任务,[x] 表示已执行的任务
-
取出待执行的任务,带上任务上下文信息,做一次 function call,这里带上的 function tools 是系统内置的可以执行不同任务的 agent,比如 search agent / code agent / data-analysis agent
-
根据 function call 的结果,调度指定的 agent 执行任务,把执行过程中产生的内容,写入到容器中的任务文件夹
-
任务执行完,由主线程,更新 http://todo.md,继续下一个任务
五. 归纳整理
-
http://todo.md 里面的任务全部执行完之后,主线程针对用户的初始需求,做一次整理输出
-
把任务的内容产物,给到用户浏览或下载(文档 / 代码 / 图片 / 链接等)
-
收集用户对任务的满意度
整个方案理下来,核心在于执行任务的 agent 设计,以及主线程的调度流程,以 search agent 为例,在处理“日本旅行计划”这个任务中,主要的执行步骤:
-
拿到 japan-trip 等关键词信息,调用谷歌第三方 API,获取 10-20 条搜索结果
-
模拟浏览器点开第一个网页,浏览网页内容,获取网页文本内容 + 浏览器截图拿到网页视觉信息
-
调用支持多模态输入的模型,输入当前任务要求,从当前浏览的网页中提取有效信息(是否有符合要求的结果,如果不满足要求,返回下一个该点击的 button 元素)
-
模拟浏览器点击 + 网页滚动行为,拿到更多的网页内容 + 视觉信息,重复几次,直到收集到的内容满足任务要求为止
-
把收集到的内容保存到任务文件夹
这个 search agent 的核心在于模拟用户浏览网页行为,需要用到无头浏览器和多模态模型。
code agent 和 data-analysis agent 相对而言比较简单:
-
根据任务需求,创建本地文件,写入代码(python 代码做数据分析,html 代码做视觉呈现)
-
通过系统调用执行代码,把执行结果保存到任务文件夹
-
通过 code-preview 服务,预览 html 文件的内容
此类 multi-agent 产品,还有一些改进的空间:
-
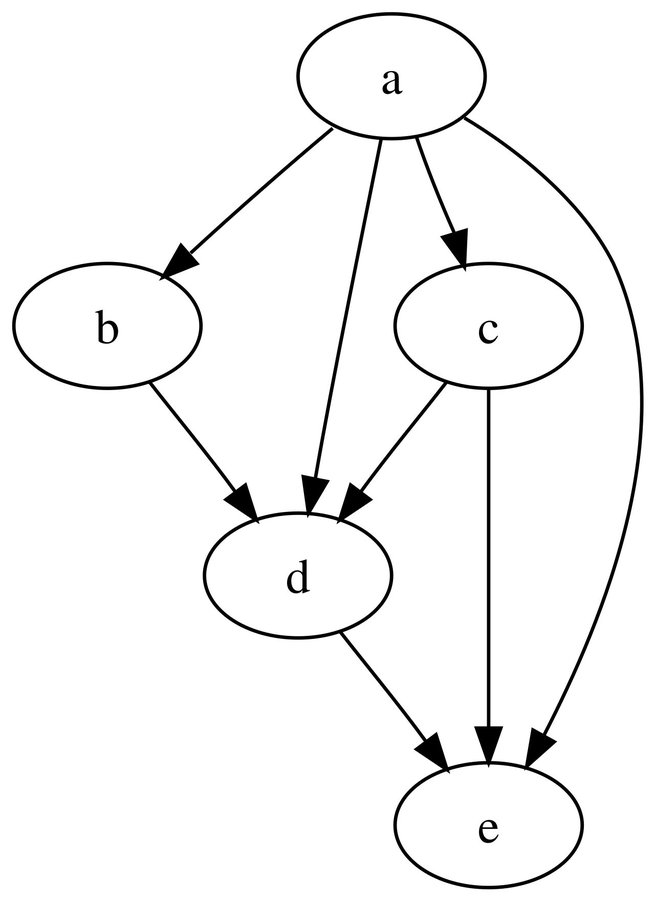
http://todo.md 的多个任务,是线性依赖关系,可以使用 DAG(有向无环图)实现更加复杂的任务依赖
-
需要引入自动化测试 agent,对任务结果进行判断和矫正,如果对某个步骤评分过低,需要回溯到之前的某个任务节点重新执行
-
允许全自动 + 用户介入的混合模式,在某个步骤执行完,先寻求用户反馈,如果几秒内没收到反馈,则自动继续运行
整体评价:manus 在工程层面做了很多工作,整体交互比其他产品好很多。技术层面,依然是没什么壁垒,对模型有比较深的依赖:
-
也许有个小模型,做任务执行前的意图识别
-
任务规划和推理,用 deepseek-r1
-
图片识别 + 代码生成,用 claude-3.7-sonnet
token 消耗会很高,能不能广泛用起来,取决于谁来负担这个成本。
最终的任务准确性和用户满意度,还需要更多的案例来说明。